In celebration of Open Data Day on March 3, 2018, we are releasing a 4 part series on how to manage an open data program.
- Part 1: DataSF’s operating manual for open data
- Part 2: How to monitor your open data portal
- Part 3: How to tame open data with standards
- Part 4: Why you need to profile your open data
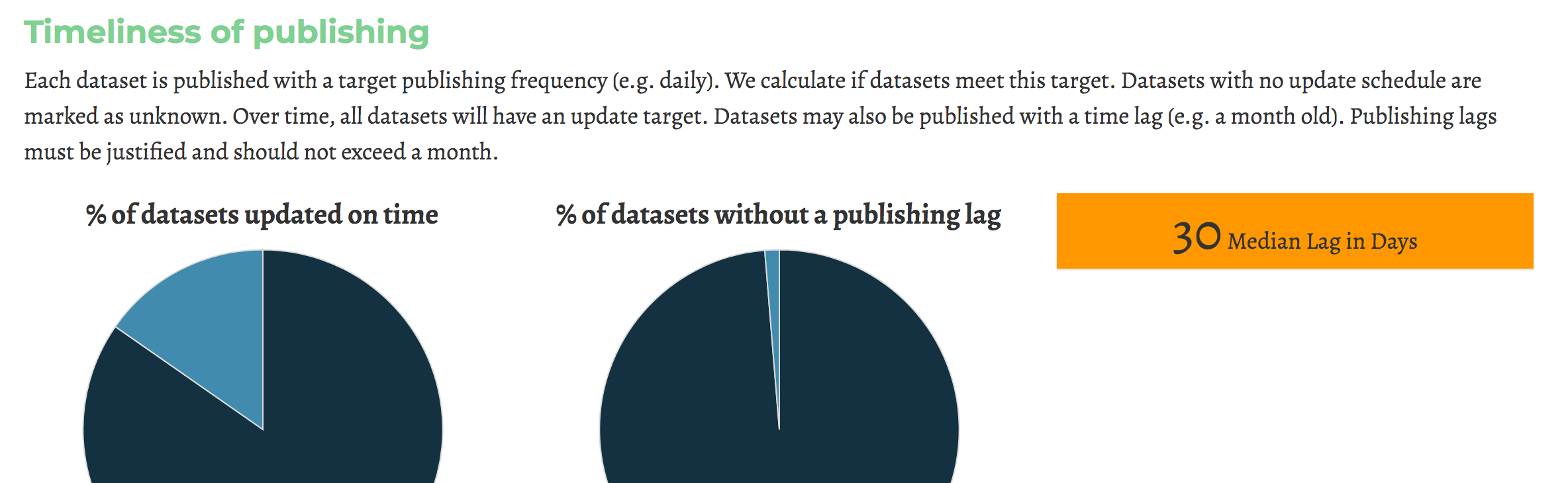
Monitoring data is essential to understand the inner workings of your open data portal. At DataSF, we strive to:
- Provide data that is usable, timely, and accessible.
- Ensure that data on the open data portal is understood, documented and of high quality.
Monitoring our open data portal helps us quantify how well we’re achieving our high level goals. At an operational level, collecting and classifying data about our portal enables our program to do the following:
- Quickly investigate and get to the bottom of data availability and quality issues.
- Receive meaningful, automated alerts about potential problems.
- Minimize service degradation and disruption.
Types of Monitoring Metrics
Monitoring metrics are collected at regular intervals to monitor our open data portal over time. For instance, a metric could record the number of records in a dataset or when a dataset was last updated. At DataSF, we collect three types of monitoring metrics:
- Open Data Activity Metrics: top level metrics that indicate create, read, update, delete and permissioning activities to data on our open data portal.
- Data Quality Metrics: high level measures that let you understand the overall quality of the data on your open data portal.
- Event Metrics: discrete, infrequent occurrences that relate to our open data portal; these can be data infrastructure events or other bugs/issues; these can be used to investigate issues across correlated systems and/or datasets.
You can read specifics about each of these monitoring metrics in a longer whitepaper.
Characteristics of Good Monitoring Metrics
Remember, metrics about your open data portal are really just data points. The data you collect about your open data portal should have four characteristics:
- Well Understood: If an issue on your open data portal arises, you don’t want to spend time figuring out what your data means. You and your team should be able to quickly determine how each metric was captured.
- Granular: One goal of collecting metrics is to be able to reconstruct the state of your open data portal at a specific point in time.
- Tagged by Scope: There are different scopes on your open data portal: the open data portal as a whole, a dataset, a field/column within a dataset, and a record within a dataset. You will want to check the aggregate health of any one of these scopes or their combination.
- Longed-Lived: It’s important to think about how long you want to retain your monitoring data. Retaining raw monitoring data for at least six months makes it easier to figure out what’s normal. Some metrics may have seasonal or monthly variations.
Using Monitoring Data for Alerts
After collecting your monitoring data, you will probably use it as a trigger to send out automated alerts and notifications. DataSF uses three levels of alerts:
- Record: something that gets recorded in the monitoring system.
- Notification: an automatically generated, moderately urgent alert that notifies someone in an unobtrusive way, such as via email or a chatbot.
- Page: an urgent alert sent to someone. Pages are designed to be invasive and immediately redirect the responder’s attention to investigate a problem or incident.
Diagnosing an Alert
Your motoring metrics will capture a symptom of an issue or problem on your open data portal. A system could have one or many causes. For example, unbeknownst to your program staff, four, frequently used public datasets have been mysteriously deleted off your open data portal in the past 24 hours. Possible causes of the datasets disappearing are your open vendor provider, the department who provided the data, an unauthorized user, etc.
Once your monitoring system has notified you about a symptom, you and your team will need to diagnose the root cause using the monitoring data that you’ve collected.
The following framework can be helpful in investigating an issue:
- Start with data activity metrics: Ask your team, “What’s the problem? How would I characterize it?” At the outset, you need to clearly describe the problem before diving deeper. Next look at the high level open data activity metrics. These will often disclose the source of problem, or at least steer your investigation in a particular direction. For instance, a user reports that there’s no crime data for the last 2 weeks. Looking at your data activity metrics, you would quickly see that the dataset hadn’t been updated in two weeks. You would also see that that owner of the dataset changed three weeks ago, helping you further hone in on the cause of the problem.
- Dive into data quality metrics: If you haven’t found the cause of the issue by inspecting your data activity metrics, examine the data quality metrics. You should be able to quickly find and peruse these metrics to look for outliers and anomalies, incomplete data or data that doesn’t make sense.
- Did something change? Next, consider events or other alerts that could be correlated with your issue. If an event was registered slightly before the problems started, investigate whether or not it’s connected to the problem.
- Fix it (and improve it for next time!): After you’ve found the root cause of the problem, fix it. Although the investigation is complete, it’s usually worth taking some time to think about how to change your system, publishing or business process to avoid similar problems in the future.
Setting up monitoring dashboards in advance of problems can greatly speed up your investigation. Dashboards can help you observe the current and recent state of your open data portal and make potential problems more visible than just looking at raw data.
Conclusions
Collect as many data portal activity, data quality and event metrics as you can. A robust monitoring program demands comprehensive metrics:
- Make sure to collect metrics with sufficient granularity so that you can reconstruct the state of your open data portal at specific point in time.
- To maximize the value of your monitoring data, tag metrics and events with several scopes and retain them for at least 6 months.
- Use your monitoring data as triggers to send out automated alerts.
- Use alerts to flag symptoms so you and your team can figure out the cause.
- Standardize your monitoring framework so you and your team can investigate problems more systematically.
- Set up dashboards ahead of time that display all of your key data portal activity and data quality metrics.
Resources to help you start
At DataSF, we’ve implemented some internal tools to monitor our portal activities and data quality on our open data portal. Check out these related repositories:
- datasf-portal-monitoring: a set of tools to generate and analyze portal activity metrics and send out related notifications, https://github.com/DataSF/datasf-portal-monitoring.
- datasf-profiler: a tool to generate data quality metrics for all public data on the DataSF open data portal, https://github.com/DataSF/datasf-profiler.
We would love to hear about your experiences monitoring your open data portal. If you have comments, questions, additions, corrections or complaints, let us know on twitter!
References
- Alexis Lê-Quôc, (2015, June 30). Monitoring 101: Collecting the right data. Retrieved from https://www.datadoghq.com/blog/monitoring-101-collecting-data
- Alexis Lê-Quôc, (2015, July 16). Monitoring 101: Investigating Performance Issues. Retrieved from https://www.datadoghq.com/blog/monitoring-101-investigation/
- Alexis Lê-Quôc, (2015, July 16). Monitoring 101: Alerting on What Matters. Retrieved from https://www.datadoghq.com/blog/monitoring-101-alerting/