
In San Francisco, we have some data (sorry, I mean a lot of data). But sadly, there is no magical red publish button. So how to go about it? Priortize your data.
We follow 4 key strategies.
Strategy 1: Department Drip
Ultimately, our departments have to set aside time and resources to publish datasets. So during our data inventory process, we asked them two key questions to help them prioritize:
- What is your sense of the relative value in publishing this data - High, Medium, or Low? (Check the questions and definitions in our Data Coordinator Guidebook).
- How do you classify this data - Public, Sensitive, or Protected?
We then assigned an initial priority level per the picture below and asked departments to revise it as needed.
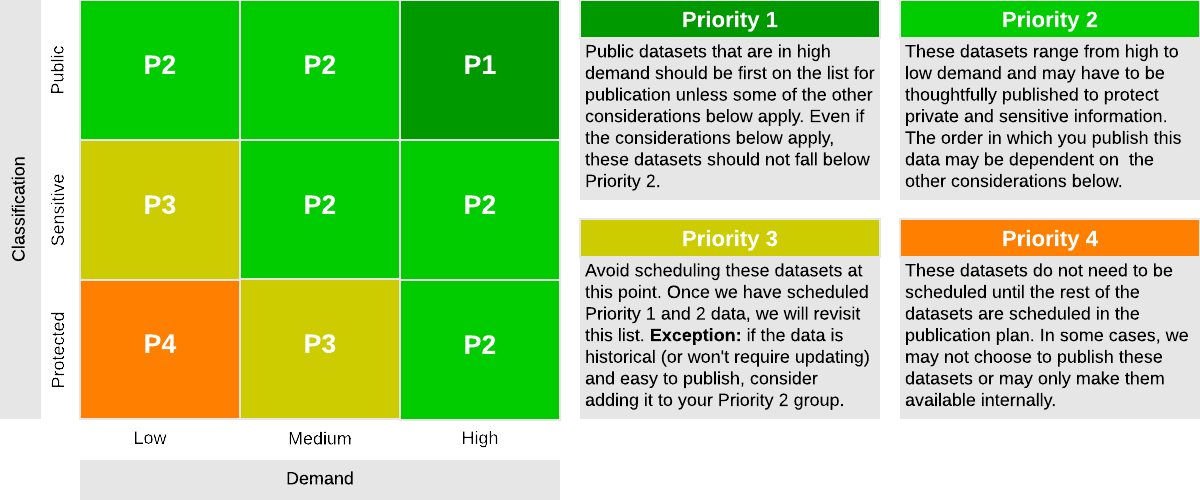
(Read more about how we did this - deep link in our guidebook).
We then asked departments to use this to create their publication plans (more on this later).
Strategy 2: Endorse a Dataset
While the department drip strategy reflects internal value and needs, we needed to also give a voice to our users - both internally and externally.
We are still building this, but basically, it works like this:
- We have this awesome data inventory
- We are building a lightweight endorsement application on top of it (more on that later)
Strategy 3: Strategic or Thematic Releases
We’ve written about this before. Strategic releases are the publication of 1 or more datasets + a data product. The Housing Data Hub is one. For strategic releases, we’ll leverage additional resources from the open data program.
Key Criteria
To be a strategic release, it must meet several key criteria:
- Address a pressing information gap or need
- Inform issues of high public interest or concern
- Tie together disparate data that may otherwise be used in isolation
- Unpack complex policy areas through the thoughtful dissemination of open data
- Pair data with the content and domain expertise that we are uniquely positioned to offer (e.g answer the questions we receive over and over again in a scalable way)
- Build data products that are unlikely to be built by the private sector
- Solve cross-department reporting challenges
Readiness Checklist
Even if an idea meets the key criteria, we need to be able to execute, so we have a readiness checklist:
- Do we have a resourced partner? Are the departments ready and able to commit resources? Is the data ready and/or departments are committed to making it ready?
- Do we have the time / bandwidth to commit?
- What type of technology development is required? Do we have the time? Can we leverage existing investments?
- Is there an opportunity to shop this around for resources?
- Are there key dependencies we can’t control? How will we mitigate?
- Can we create an agreed upon project charter including:
- Clear scope
- Resource commitment from us and departments, including roles and responsibilities
- Phases of work and estimated timelines
- During production / work - can we clearly specify processes? In particular, if there is content development, do we have the review process designed and agreement on tone/editing rights etc?
Strategy 4: Divide and Conquer
As part of our strategic plan, we created data automation as a service. The idea is to provide data automation services to remove the human from data updates. Both strategic releases and department publishing plans and drip strategies feed our data automation queue. But the divide and conquer strategy emerged after analyzing our systems list created during the course of the inventory.
In analyzing the list, we identified departments that are excellent candidates for wholesale automation - i.e. we can swoop in and automate all (or alot of) their data in a single project.
What about you? How do you prioritize data for publication?