We’ve created some guidelines for publishing data on the City’s open data catalog. Following these guidelines will help maximize the value of publishing your data and support a consistent experience for data users.
Publish data in the rawest form possible
One of the cool things about open data is that people are always surprising us by what they do with it. Publishing data in the rawest form possible helps make the data as flexible as possible.
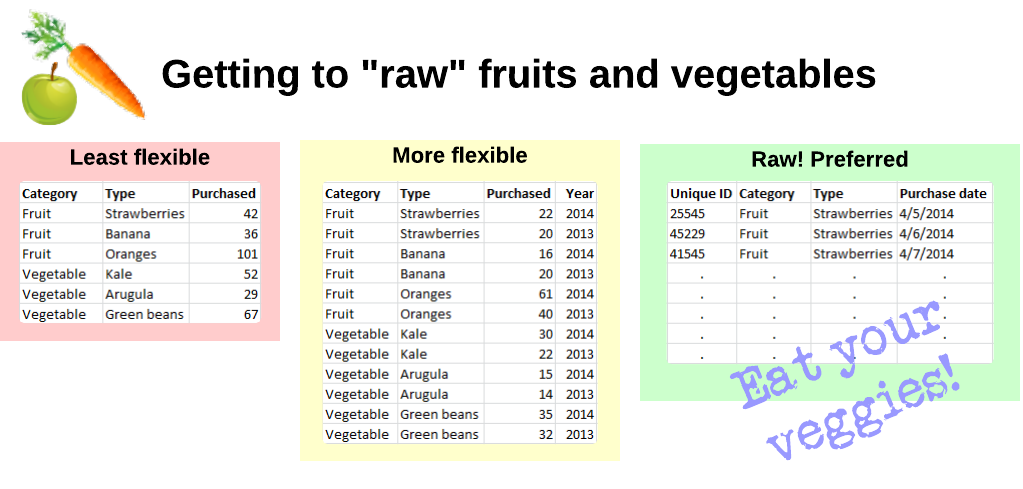
For example, if you collect data on fruit and vegetable purchases, you could publish summarized or raw data. In the picture below, if you publish the raw data - you can derive the other two. Publishing your raw data is the best way to foster new uses! We understand, of course, your ability to publish in raw formats may be limited by legal and privacy constraints, so that’s why it’s the rawest form possible.
Don’t publish data from another department
This is a corollary to the previous - if your department doesn’t manage the data, you should not publish it. Otherwise we won’t be able to effectively respond to data questions or ensure that the right or best data is being published. There may be occasions when multiple departments contribute to a single dataset, but we’ll handle these on a case by case basis.
Publish address or point data in tabular format - not as a shapefile
Most users are confused by or don’t have the resources to use shapefiles. (Whereas our savvier users find it simple to go from tabular to mapped data). Tabular data makes it easier for most users to use. Plus, our open data platform allows us to create maps on top of the tabular view anyway. SF crime incident data, for example, is published in this way and users can make a bunch of maps from it, like this one. Overall, this increases the flexibility and usability of those point layer datasets.
Include the data steward in the publishing process
Data stewards are responsible for the dataset and can answer questions about the data and help make decisions about how to publish it. You should not be publishing a dataset without input from the data steward. They are key to helping us actively manage and answer dataset questions.
Publish non-point geographic data natively
Upload geographic lines or polygons so that they are hosted natively on the platform (versus a zipped shapefile). We are moving toward native hosting of all datasets to create a more consistent platform experience for users.
For less volatile datasets that change very little or are historical in nature, you can upload the shapefile directly. For more complex, changing datasets, you can load ESRI Map Layer links to keep the dataset synced to a source mapping service.
Publish data about geographic boundaries in keyed tables - not as a shapefile
If you have a dataset by a certain geography (e.g. neighborhood, tract or supervisor district) publish the data as a table using the geography as a key field. This will allow others to access the data regardless of GIS capabilities.
If your dataset is a novel analysis and includes a series of indicators, publish it as a single dataset and include documentation on the analysis. This will help signal to the user that this is an analysis dataset that represents a point in time and not a source for the original data. See DPH’s Community Resiliency Indicator system for an example of this.
Automate data publishing where appropriate
In order to maintain timely data available across the City, we prefer automation and provide a set of services to help in the automation process. The best way to start publishing data is to fill out a Publisher Packet for the dataset completely. The information in this packet will help the open data team work with you to determine the most appropriate data publishing method. You can read more about data automation services, if you want to learn more about the options.
Responsibly publish private or sensitive data
If your dataset has private or sensitive data, there are several ways to responsibly publish this data. We will help you with this - you are not alone!
During the process of publication, we will work with you to implement the appropriate method. So at this stage, focus on flagging areas of concern - not on how to implement it. During the publishing process we ask you to identify concerns and have introduced a new process to guide you through identifying the appropriate publishing method. The table below provides a quick overview of the basic methods we use.
| Method | What it is | Best for |
|---|---|---|
| Column Removal | Remove the privacy implicating columns. The simplest way to avoid any privacy issues, is to simply not publish the columns that include private data. For example, if a dataset is a list of users and includes their name, address or other information, you can simply remove those columns from the dataset. | Datasets that include individual information that is not necessary for consuming and understanding the data. |
| Obfuscation | Mask or transcribe the data. Obfuscation can happen in a number of ways but a common case is with address data. Sometimes we want to retain a proxy of the address without aggregating the data. | Datasets that include individual information that is not necessary for consuming and understanding the data. |
| Banding | Group the data. Banding is a way to obscure individual values. For example, instead of publishing age, you can publish age group. Other examples of banding include time (date to month to quarter) or race (breakouts to other). | Datasets where individual record data is important to publish but where too much detail can make it easy to identify individuals with uncommon mixes of characteristics. |
| Aggregation | Summarize the data based on a data property. Sometimes de-identifying the data is not sufficient. Your data might need to be aggregated either by geography or some other factor such as a category in the dataset. | Datasets where the individual records pose a privacy risk even if the identifying columns are removed. A common example of this is health related data. If the individual records (rows) are important to publish, use one of the other methods. |